Abstract
Generating realistic, dyadic talking head video requires ultra-low latency. Existing chunk-based methods require full non-causal context windows, introducing significant delays. This high latency critically prevents the immediate, non-verbal feedback required for a realistic listener. To address this, we present DyStream, a flow matching-based autoregressive model that could generate video in real-time from both speaker and listener audio. Our method contains two key designs: (1) we adopt a stream-friendly autoregressive framework with flow-matching heads for probabilistic modeling, and (2) We propose a causal encoder enhanced by a lookahead module to incorporate short future context (e.g., 60 ms) to improve quality while maintaining low latency. Our analysis shows this simple-and-effective method significantly surpass alternative causal strategies, including distillation and generative encoder. Extensive experiments show that DyStream could generate video within 34 ms per frame, guaranteeing the entire system latency remains under 100 ms. Besides, it achieves state-of-the-art lip-sync quality, with offline and online LipSync Confidence scores of 8.13 and 7.61 on HDTF, respectively. The model, weights and codes are available.
System pipeline
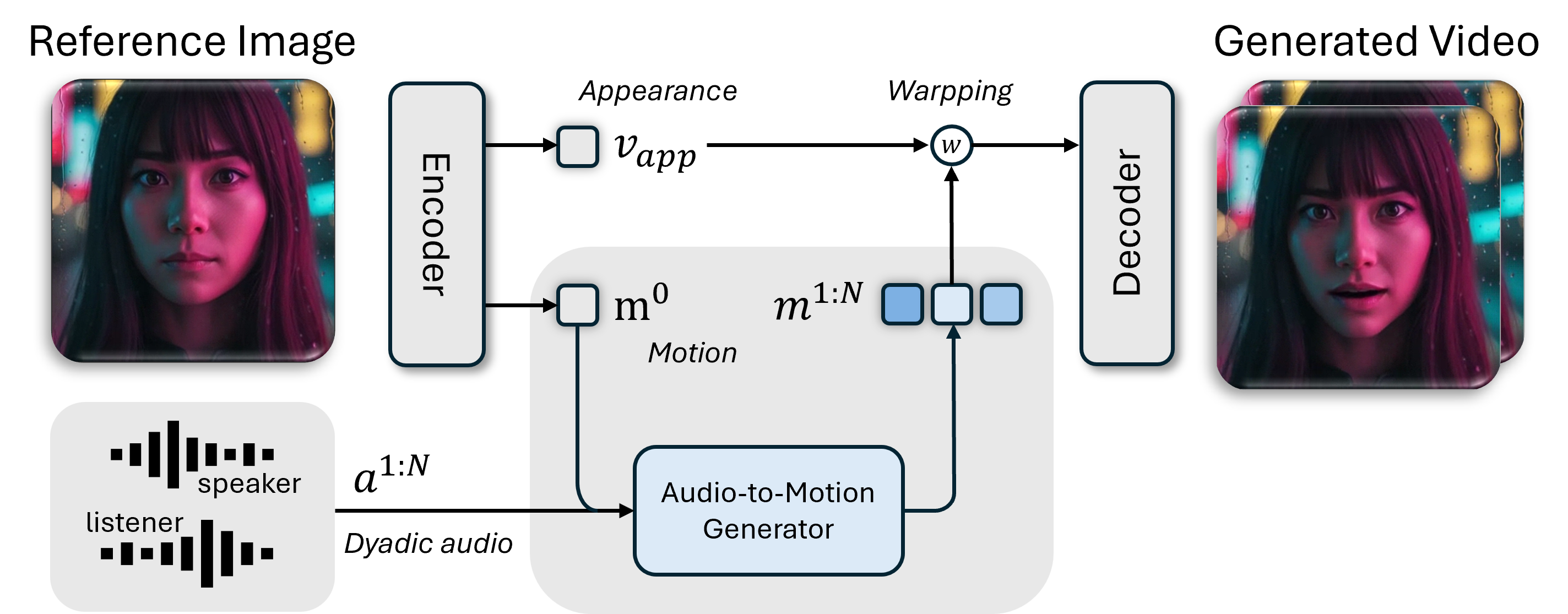
DyStream generates talking-head videos from a single reference image and dyadic stream. First, an Autoencoder disentangles the reference image into a static appearance feature vapp and an initial, identity-agnostic motion feature m0. Next, the Audio-to-Motion Generator takes the initial motion m0 and the audio stream as input to generate a new sequence of audio-aligned motion features m1:N. Finally, the Autoencoder's decoder synthesizes the output video by warping the appearance feature vapp according to the generated motion sequence m1:N.
The Architecture of Our Audio-to-Motion Generator
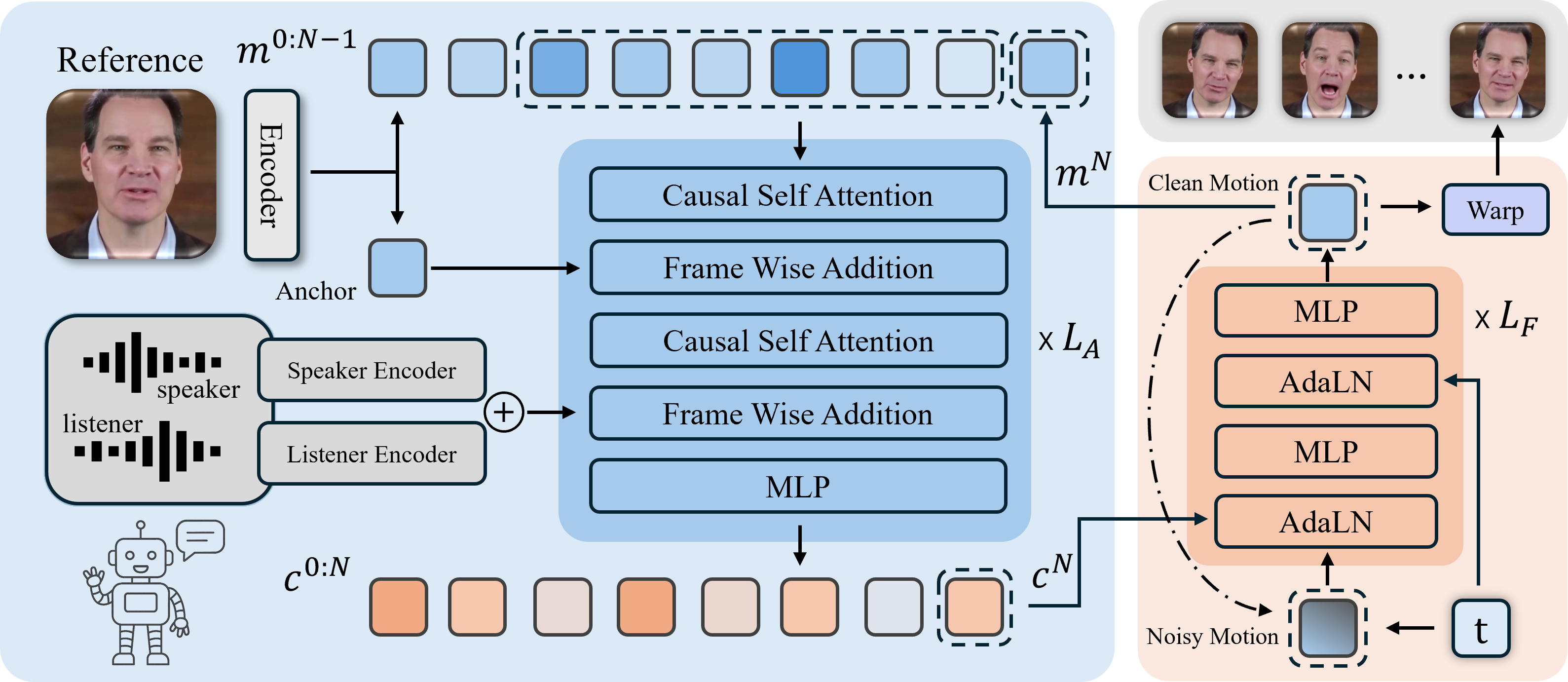
Our model comprises two core modules: an autoregressive network (blue) and a flow matching head (orange). The autoregressive network, built from causal self-attention and MLP blocks, processes the audio, anchor, and previous motion inputs to generate a conditioning signal cN. This signal is fed into the flow matching head, a stack of MLPs and AdaLN layers. Here, it is injected via AdaLN to guide a multi-step flow matching process to produce the final motion mN. Finally, the newly generated motion mN is used to warp the reference image into the output frame, while simultaneously being fed back into the autoregressive network as input for the subsequent generation.
Generated Videos
Dyadic Audio
Our method can generate motion-adapted synthesis results for the same reference image based on different audio inputs.
Compare with INFP
Because there is no open-source work that supports dyadic audio as input, we reimplement INFP and compare it with our method. For each group of video, the left is ours, the right is INFP.
Compare with Offline Model
Each group of videos, from left to right, shows the results of: (1) our method result in real-time setting; (2) offline model result in offline setting; (3) offline model result in real-time setting.
Ablation on anchor
Ablation on anchor: ach group of videos, from left to right, shows the results of (1) no anchor; (2) random motion sampled from whole frames; (3) our method (anchor sampled from the last 10 frames).
In the wild image from FFHQ
We test the performance of our method on the images from FFHQ dataset.
In the wild images from Nanobanana
We also test the performance of our method on the images generated by image generation model like Nanobanana.